Background
- Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scare, making it challenging for discriminatively trained models to perform adequately.
- The ability to learn effectively from raw text is crucial to alleviating the dependence on supervised learning in natural language processing (NLP). The most compelling evidence for this so far has been the extensive use of pre-trained word embeddings. Leveraging more than word-level information from unlabeled for two main reasons (How to train pre-trained models && How to transfer the learned models to other specific tasks):
- It is unclear what type or optimization objectives are most effective at learning text representations that are useful for transfer.
- There is no consensus on the most effective way to transfer these learned representations to the target task.
Motivation
- Our goal is to learn a universal representation that transfers with little adaption to a wide range of tasks.
- We explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning.
- First, we use a language modeling objective on the unlabeled data to learn the initial parameters of a neural network model.
- Subsequently, we adapt these parameters to a target task using the corresponding supervised objective.
Model
From background and motivation, the model is composed of two parts: unsupervised pre-training and supervised fine-tuning.
Unsupervised Pre-training
Input: A large text corpora
Output: A language model trained on the corpora
Traing Objective
Given an unsupervised corpus of tokens $\mathcal{U}={u_1, …, u_k}$, we use a standard language modeling objective to maximize the following likelihood:
Training Methods
In the experiments, we adopt a multi-layer Transformer decoder (suitable for single-directional models) for the language model. The training network is as follows:
where $U=(u_k, …, u_{i-1})$ is the context vector of tokens, $n$ is the number of layers, $W_e$ is the token embedding softmax, and $W_p$ is the position embedding matrix.
For the unsupervised pre-training, it’s just a language model and the training process is easy to understand. The language model will predict every word in the corpora during training.
Supervised Fine-tuning
After training the unsupervised model, we can save the model parameters except the last output layer. Word embedding layer and representation layers (transformer_block) are saved.
During supervised fine-tuning process, we transfer the saved model to specific tasks. The parameters in transformer_block can be changed or fixed.
The inputs are passed through the pre-trained model to obtain the final transformer_block’s activation $h_l^m$ ( $l$ is the block layer and $m$ is the token position), which is then fed into an added linear output layer with parameters $W_y$ to predict $y$:
During fine-tuning process, the objective is :
In unsupervised pre-training, the objective is $L_1 (\mathcal{U})$, while in the supervised fine-tuning, the objective is $L_2 (\mathcal{C})$. $L_1$ represents the effect of how the language model can model the unlabeled corpora. $L_2$ represents how the pre-trained model can be adapted to specific tasks.
We additionally found that including language modeling as an auxiliary objective to the fine-tuning helped learning by (a) improving generalization of the supervised model, and (b) accelerating convergence. So the new objective in supervised fine-tuning is:
They also add a delimiter tokens Delim in the embedding matrix and will be trained on the specific tasks.
Task-Specific Input Transformations
The pre-trained model has been saved. The next step is to adapting the model to different tasks.
The input sequences are fed into the language model and will output vector representations in the last layer. Then we can adopt the vectors to perform specific tasks like classification.
If the inputs are single sentences, the model will be trained easily. What about other circumstances? Two inputs, or several choices? This paper gives an elegant solution.
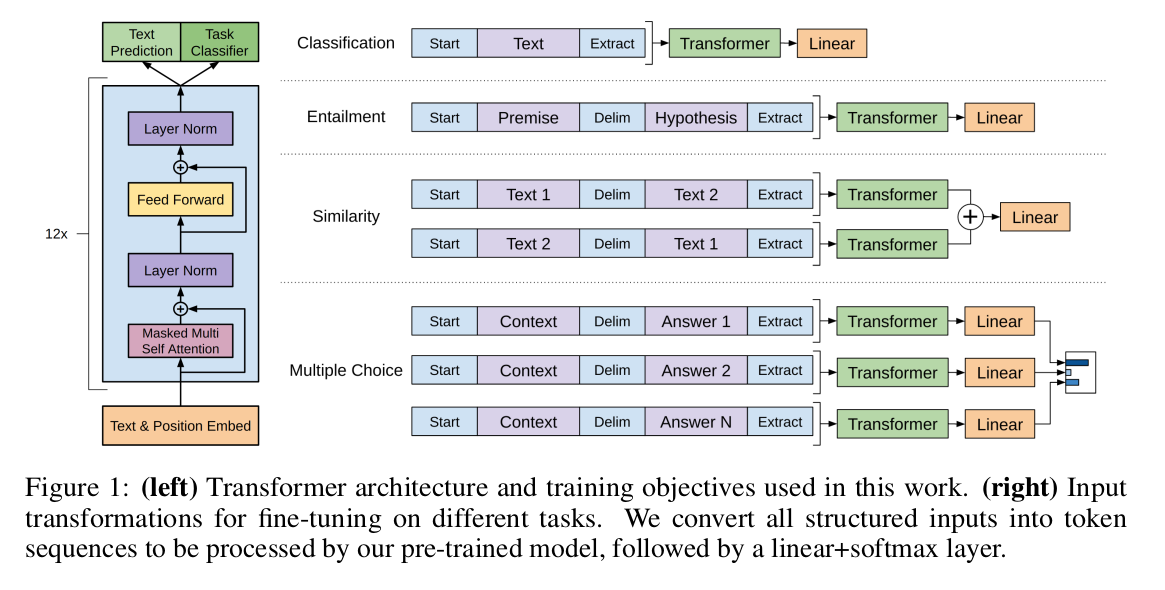
In Figure 1:
- One input: just feed it to the model and get the result
- Two inputs: add a
Delimbetween two inputs and feed it to the model - Two inputs and similarity: there are no inherent orders between sequences. So the input sequences contain both possible sentence orderings and process each independently to produce two sequence representation $h_l^m$, which are added element-wise before being fed into the linear output layer
- Multiple Choice: Concatenate each choice to the given text and process them dependently to produce multiple $h_l^m$ and they are combined together to predict the results.
Emmm… This paper is well written and easy to understand. For coding implementation, I will not write. Err… I will write BERT in details since BERT performs much better that GPT.